
Harnessing Data at Scale: Character.AI's Transition to WarpStream
Character.AI operates at scale, supporting over 20 million monthly active users across our services. Despite being a relatively small company, our services have significant and complex data storage needs. This data is distributed across various online data stores, and transferred to near real-time and offline data stores for purposes such as analytics.
Background
Character.AI primarily relies on a major hyperscaler’s public cloud services. Our training and serving clusters are hosted on this infrastructure. Given our small team size, we focus on building essential services and opt to purchase additional capabilities wherever feasible.
Our Extract, Transform, and Load (ETL) process is batch-oriented and utilizes the Data Build Tool (DBT). However, certain use cases necessitated a more efficient transfer of data from our online datastore to our data warehouse. Although the messaging service offered by our hyperscaler is a fully managed and highly scalable solution, it presents challenges when integrating with tools like Spark, and it incurs substantial costs.
Initially, our focus was on research, making batch-oriented workflows sufficient for our needs. We employed a few messaging pipelines primarily as a Change Data Capture (CDC) alternative, since some online data stores lacked a reliable CDC mechanism.
Additionally, our unit economics differ from those of traditional software companies. Our GPU clusters are equipped with ample CPUs and RAM, providing us considerable flexibility in managing our computing resources.
What Changed?
As our product evolved, we aimed to leverage real-time data instead of relying solely on periodically uploaded data to our data warehouse. This shift allows us to refine our understanding of user experiences and derive crucial user insights. However, this transition requires intelligently managing a significantly higher throughput of real-time data. We also sought to explore various open-source and industry-leading technologies to better serve our customers while remaining cost-effective.
Path to WarpStream
After assessing our initial requirements and identifying strong use cases that would benefit from open-source tooling, we concluded that our new pipeline needed to be Kafka compliant. We required a solution capable of handling our scale, ensuring reliability, and allowing us to utilize our own compute resources through a Bring Your Own Cloud model.
Upon exploring various options, we discovered WarpStream, which serves as a Kafka facade on top of an Object Store bucket. While it may introduce slightly higher producer latency, it significantly enhances ease of operations, cost-effectiveness, and simplicity. Following an initial test, we decided to build a new use case on WarpStream as our Proof of Concept (PoC). WarpStream's unique stateless agent architecture, its integration with GCS, and overall operational ease made it the ideal choice for our needs.
Use Case I: Prompts
At Character.AI, users and systems generate a meaningful amount of data. Setting up an application using the WarpStream-provided helm chart was straightforward and worked seamlessly. Additionally, configuring our tokenizer to send prompts to WarpStream using a simple Kafka client was also easy.
However, getting data into WarpStream was just one part of the equation; we also needed to transfer this data into our data warehouse. To achieve this, we utilized WarpStream’s Managed Data Pipelines, powered by Bento, an open-source stream processing framework. These Managed Data Pipelines operate within our cloud account, eliminating the need for additional infrastructure, and can be configured with zero code via a simple YAML file.
Managed Data Pipelines capitalize on the stateless nature of WarpStream’s agents, allowing us to split workloads while sharing data across agent groups (see more about agent groups here). By deploying additional stateless agents and modifying our YAML configuration, we could specify which Pipeline Group our pipelines would run on.
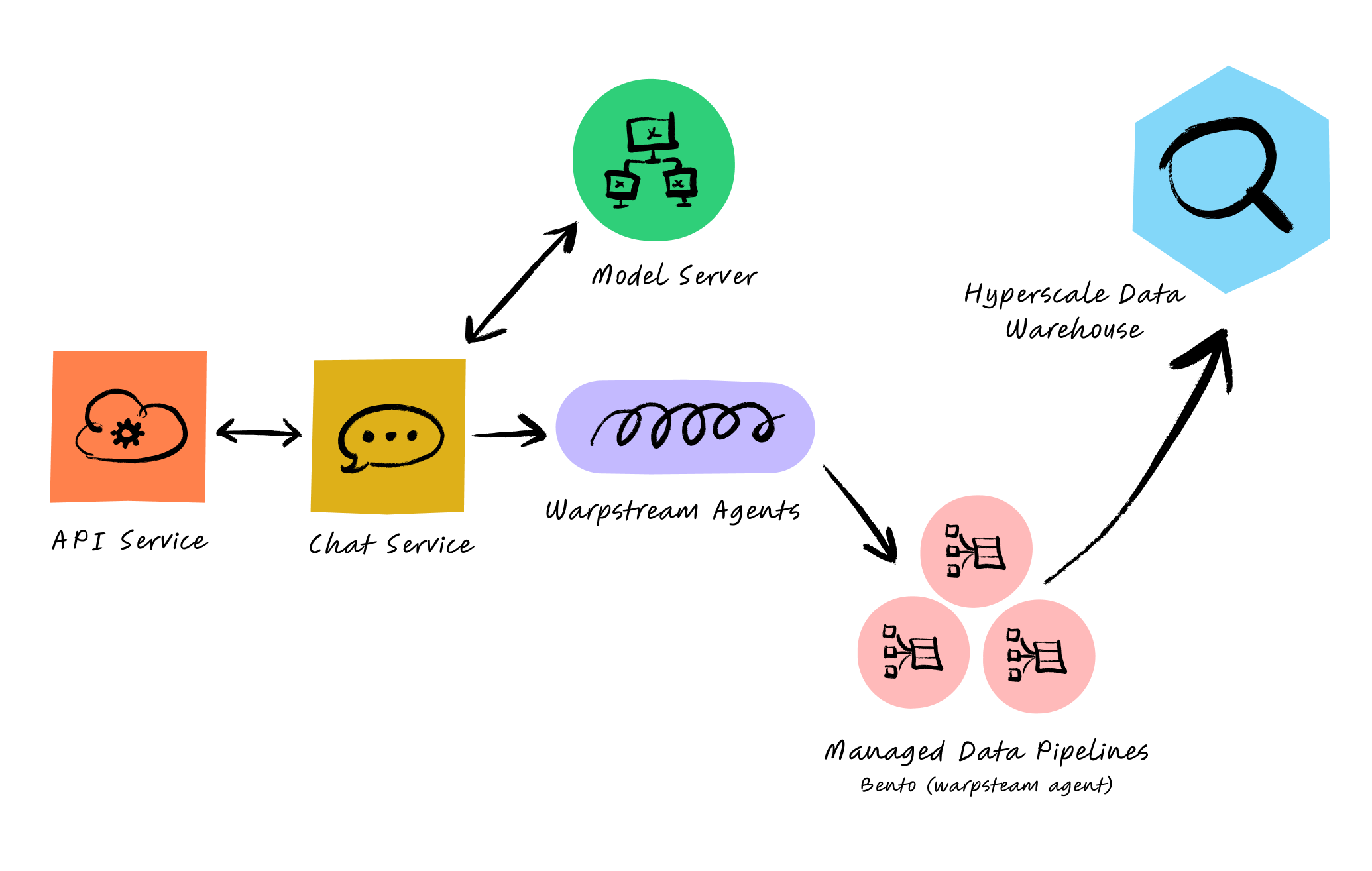
This architecture enables us to stream over 3 GiBs of data per second directly into our data warehouse for further analysis. Additionally, WarpStream’s Kafka-compatible durable log allows us to attach extra data consumers to this feed, facilitating easy integration for any team looking to process data.
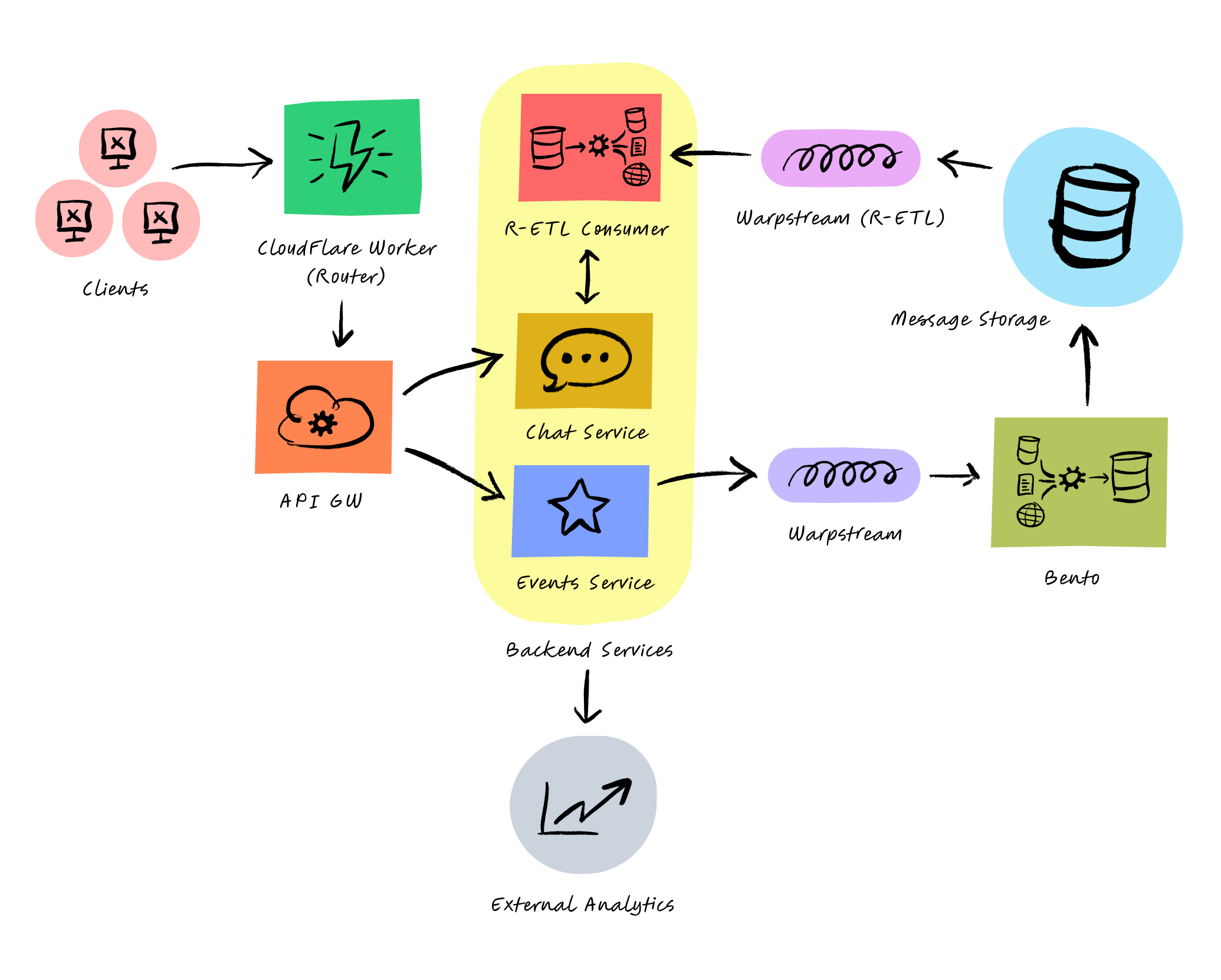
Use Case II: Reducing Analytics Costs
Given that we operate both mobile and web applications, we handle significant external analytics. However, our third-party vendor charges based on the number of events processed, which proved unsustainable as our user base grew. We sought a more scalable and cost-effective solution using WarpStream.
Once again, we leveraged Managed Data Pipelines for this use case. By employing these pipelines for ETL and storing the data in WarpStream, we successfully built a scalable, near-real-time analytics engine to supplement our external analytics vendor.
Conclusion
Character.AI's journey in data management reflects our commitment to leveraging innovative technologies that enhance operational efficiency and reduce costs. By transitioning to WarpStream and adopting a real-time data approach, we have not only improved our data processing capabilities but also positioned ourselves to better serve our users. As we continue to grow, we remain dedicated to exploring new solutions that align with our mission, ensuring we can scale effectively while prioritizing user insights and experience.